Covariates¶
Covariates Design from EpiViz¶
EpiViz-AT classifies covariates as country and study types. The country are 0 or 1 and are specific to the bundle. The country are floating-point values defined for every age / location / sex / year.
The strategy for parsing these and putting them into the model is to
split the data download and normalization from construction of model priors.
The EpiVizCovariate is the information part.
The EpiVizCovariateMultiplier is the model prior part.
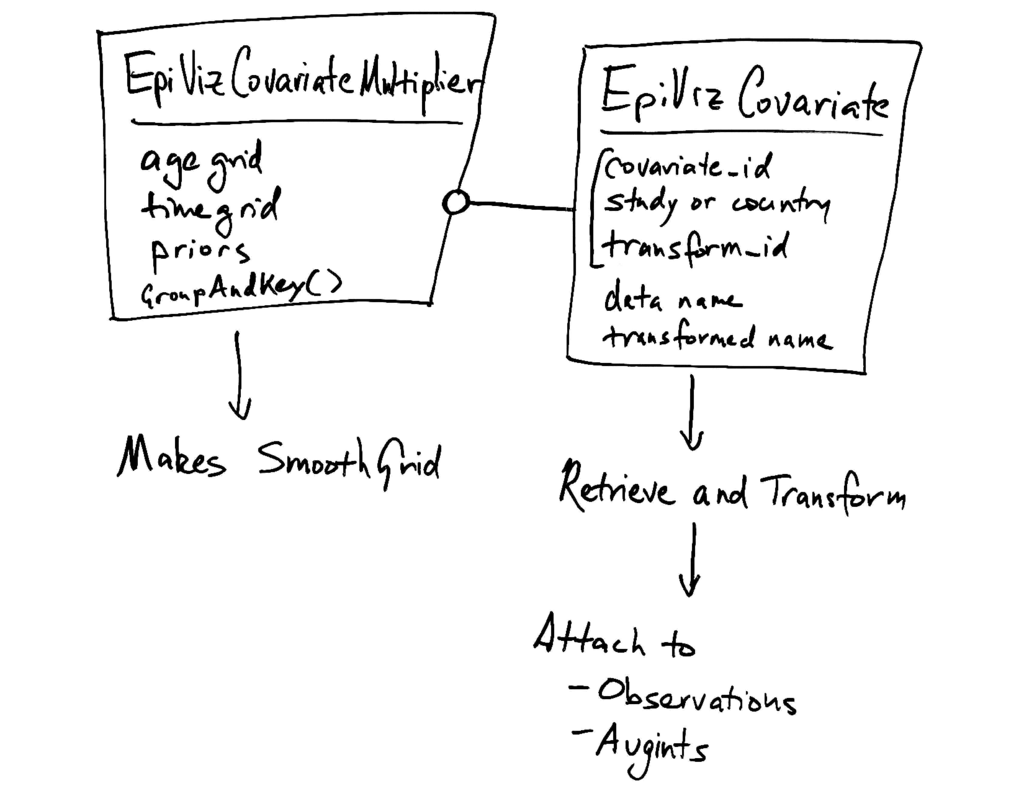
For reading data, the main complication is that covariates have several IDs and names.
study_covariate_idandcountry_covariate_idmay be equal for different covariates. That is, they are two sets of IDs. We have no guarantee this is not the case (even if someone tells us it is not the case).In the inputs, each covariate has a
short_name, which is what we use. The short name, in other inputs, can contain spaces. I don’t know that study and country short names are guaranteed to be distinct. Therefore…We prefix study and country covariates with
s_andc_.Covariates are often transformed into log space, exponential space, or others. These get
_log,_exp, or whatever appended.When covariates are put into the model, they have English names, but inside Dismod-AT, they get renamed to
x_0,x_1,x_....
-
class
cascade_at.inputs.utilities.covariate_specifications.EpiVizCovariate(study_country, covariate_id, transformation_id)[source]¶ Bases:
objectThis specifies covariate data from settings. It is separate from the cascade.model.Covariate, which is a Dismod-AT covariate. EpiViz-AT distinguishes study and country covariates and encodes them into the Dismod-AT covariate names.
-
transformation_id¶ Which function to apply to this covariate column (log, exp, etc)
-
untransformed_covariate_name¶ The name for this covariate before transformation.
-
property
spec¶ Unique identifier for a covariate because two multipliers may refer to the same covariate.
-
property
name¶ The name for this covariate in the final data.
-
-
class
cascade_at.inputs.utilities.covariate_specifications.EpiVizCovariateMultiplier(covariate, settings)[source]¶ Bases:
object- Parameters
covariate (EpiVizCovariate) – The covariate
settings (StudyCovariate|CountryCovariate) – Section of the form.
-
property
group¶ The name of the DismodGroups group, so it’s alpha, beta, or gamma.
-
property
key¶ Key for the
DismodGroupsobject, so it is a tuple of (covariate name, rate) or (covariate name, integrand) where rate and integrand are strings.
-
cascade_at.inputs.utilities.covariate_specifications.create_covariate_specifications(country_covariate, study_covariate)[source]¶ Parses EpiViz-AT settings to create two data structures for Covariate creation.
Covariate multipliers will only contain country covariates. Covariate specifications will contain both the country and study covariates, which are only the ‘sex’ and ‘one’ covariates.
>>> from cascade_at.settings.base_case import BASE_CASE >>> from cascade_at.settings.settings import load_settings >>> settings = load_settings(BASE_CASE) >>> multipliers, data_spec = create_covariate_specifications(settings.country_covariate, settings.study_covariate)
- Parameters
country_covariate (
List[CountryCovariate]) – The country_covariate member of the EpiViz-AT settings.study_covariate (
List[StudyCovariate]) – The study_covariate member of the EpiViz-AT settings.
- Return type
(typing.List[cascade_at.inputs.utilities.covariate_specifications.EpiVizCovariateMultiplier], typing.List[cascade_at.inputs.utilities.covariate_specifications.EpiVizCovariate])
- Returns
The multipliers are specification for making SmoothGrids.
The covariates are specification
for downloading data and attaching it to the crosswalk version and average integrand
tables. The multipliers use the covariates in order to know the name
of the covariate.
The following class is a wrapper around the covariate specifications that makes them easier to work with and provides helpful metadata.
Definition of Study and Country¶
There are three reasons to use a covariate.
- Country Covariate
We believe this covariate predicts disease behavior.
- Study Covariate
THIS IS DEPRECATED: the only study covariates are sex and one, described below.
The covariate marks a set of studies that behave differently. For instance, different sets of measurements may have different criteria for when a person is said to have the disease. We assign a covariate to the set of studies to account for bias from study design.
- Sex Covariate
This is usually used to select a subset of data by sex, but this could be done based on any covariate associated with observation data. In addition to being used to subset data, the sex covariate is a covariate multiplier applied the same way as a study covariate.
- One Covariate
The “one covariate” is a covariate of all ones. It’s treated within the bundle management system as a study covariate. It’s used as a covariate on measurement standard deviations, in order to account for between-study heterogeneity. A paper that might be a jumping-off point for understanding this is [Serghiou2019].
A covariate column that is used just for exclusion doesn’t need a covariate multiplier. In practice, the sex covariate is used at global or super-region level as a study covariate. Then the adjustments determined at the upper level are applied as constraints down the hierarchy. This means there is a covariate multiplier for sex, and its smooth is a grid of constraints, not typical priors.
Dismod-AT applies covariate effects to one of three different variables. It either uses the covariate to predict the underlying rate, or it applies the covariate to predict the measured data. It can be an effect on either the measured data value or the observation data standard deviation. Dismod-AT calls these, respectively, the alpha, beta, and gamma covariates.
As a rule of thumb, the three uses of covariates apply to different variables, as shown in the table below.
Use of Covariate |
Rate |
Measured Value |
Measured Stddev |
|---|---|---|---|
Country |
Yes |
Maybe |
Maybe |
Study |
Maybe |
Yes |
Yes |
Sex (exclusion) |
No |
Yes |
No |
Country and study covariates can optionally use outliering. The sex covariate is defined by its use of regular outliering. Male and female data is assigned a value of -0.5 and 0.5, and the mean and maximum difference are adjusted to include one, the other, or both sexes.
Policies for Study and Country Covariates¶
Sex is added as a covariate called
s_sex, which Dismod-AT translates tox_0for its db file format. It is -0.5 for women, 0.5 for men, and 0 for both or neither. This covariate is used to exclude data by setting a reference value equal to -0.5 or 0.5 and a max allowed difference to 0.75, so that the “both” category is included and the other sex is excluded.The
s_onecovariate is a study covariate of ones. This can be selected in the user interface and is usually used as a gamma covariate, meaning it is a covariate multiplier on the standard deviation of measurement data. Its covariate id is 1604, and it appears in the db file asx_1with a reference value of 0 and no max difference.
- Serghiou2019
Serghiou, Stylianos, and Steven N. Goodman. “Random-Effects Meta-analysis: Summarizing Evidence With Caveats.” Jama 321.3 (2019): 301-302.
Country Covariate Data¶
To grab the data for the covariates, we use this class that is part of the core data inputs.
-
class
cascade_at.inputs.covariate_data.CovariateData(covariate_id, demographics, decomp_step, gbd_round_id)[source]¶ Bases:
cascade_at.inputs.base_input.BaseInputGet covariate estimates, and map them to the necessary demographic ages and sexes. If only one age group is present in the covariate data then that means that it’s not age-specific and we want to copy the values over to all the other age groups we’re working with in demographics. Same with sex.
-
configure_for_dismod(pop_df, loc_df)[source]¶ Configures covariates for DisMod. Completes covariate ages, sexes, and locations based on what covariate data is already available.
To fill in ages, it copies over all age or age standardized covariates into each of the specific age groups.
To fill in sexes, it copies over any both sex covariates to the sex specific groups.
To fill in locations, it takes a population-weighted average of child locations for parent locations all the way up the location hierarchy.
- Parameters
pop_df (
DataFrame) – A data frame with population info for all ages, sexes, locations, and yearsloc_df (
DataFrame) – A data frame with location hierarchy information
-
Because study covariates are deprecated, we don’t need to get data for those.
Instead, in the MeasurementInputs
class we just assign the sex and one covariate values on the fly.
Covariate Interpolation¶
When we attach covariate values to data points, we often need to interpolate across ages or times because the data points don’t fit nicely into the covariate age and time groups that come from the GBD database.
The interpolation happens inside of
MeasurementInputs,
using the following function that creates a
CovariateInterpolator
for each covariate.
-
cascade_at.inputs.utilities.covariate_weighting.get_interpolated_covariate_values(data_df, covariate_dict, population_df)[source]¶ Gets the unique age-time combinations from the data_df, and creates interpolated covariate values for each of these combinations by population-weighting the standard GBD age-years that span the non-standard combinations.
- Parameters
data_df (
DataFrame) – A data frame with data observations in itcovariate_dict (
Dict[str,DataFrame]) – A dictionary of covariate data frames with covariate names as keyspopulation_df (
DataFrame) – A data frame with population in it
- Return type
DataFrame
-
class
cascade_at.inputs.utilities.covariate_weighting.CovariateInterpolator(covariate, population)[source]¶ Bases:
objectInterpolates a covariate by population weighting.
- Parameters
covariate (
DataFrame) – Data frame with covariate informationpopulation (
DataFrame) – Data frame with population information
Covariate Multipliers¶
All of the above sections involve pre-processing of the EpiViz-AT settings and covariate data. This is all so that we can make a covariate correctly in the dismod model specifications.
For the “covariate multiplier” that uses all of this information and converts it into something that dismod can understand, see Covariate Multipliers.